Distributed Workload Management Cont....
In the distribute workload management, so far we discussed about how we can store and operate on DAGs. We have created separate modules for individual tasks. Mock orchestrator mimics requests based on received response from tasks. We used neo4j graph database to store DAGs, but these DAGs were used to store series of task types for particular type of experiment. In a class discussion, we finally come to a consensus where we discovered neo4j can be used in a better way to serve different aspect of workflows. In an earlier design we did not really consider how well system can react to unexpected failures? how an experiment can be recovered from the state where it was stopped before?
There could be number of microservices involved and to create a task context orchestrator may need to interact with multiple databases/microservices. In this scenario, if anything goes wrong for any reason and if we are not maintaining a task context its a burden on orchestrator to gather data from different services.
Considering all these factors, we decided to exploit neo4j in a better way by storing required information for task execution in nodes of a graph.
Each node would store task context along with some metadata,

When experiment is submitted, based on experiment type DAG is created and stored in neo4j with experiment id as a relationship between nodes. Following is the example of how DAGs are actually stored in database. On a right side, we have master DAGs, which store series of tasks for different types of experiments with type being the relationship type between nodes. On the other hand we have live DAG which has nodes filled with task context and required metadata with expId being the relationship type.
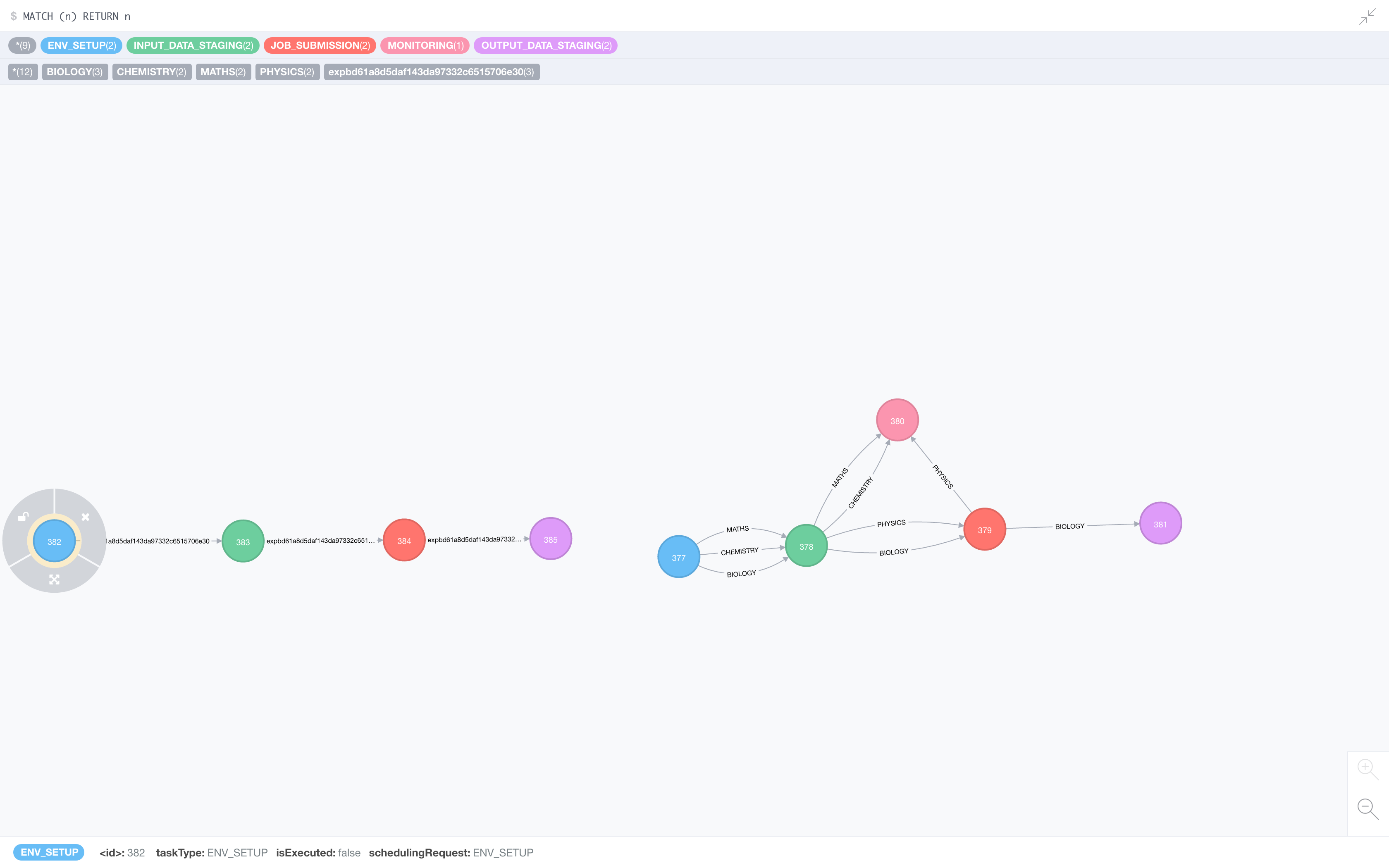
We are also using ZK to store currently executing experiments. ZK maintains nodes with experiment id as a name. Whenever experiment completes, corresponding ZK node is deleted. So even if system crashes we can recover experiments which were not completely executed.
/running-exp-dir
–/exp1
–/exp2
–/exp5
–/exp13
In case of recovery, if we know experiment id, neo4j database can be queried to get next node that needs to be executed from the DAG, as mentioned earlier this node has all the required information for task execution. Once particular task is executed, node is marked by setting isExecuted = ‘true’. In this way, DAG is executed until last node in a DAG is executed when we mark experiment as completed. In case of recovery, DAG is queries to get last incompelete node (where isExcecuted=’false’) and we start from there. We are also maintaing audit trail of individual tasks and entire experiment throughout the lifecycle.
Github Commits
My contribution is tracked here.
Contribution to Airavata
Gourav and I have started implementing proposed framework in airavata. The first step towards that was to segregate task implementations in independent moules, we have been able to create these modules, now the challenge is to refactor gfac engine and remove direct registry dependency from these tasks.
Git Commits
My contribution is tracked here.
Apart from that, there are quite a few tools out there which can be handy and do most of the part what we are trying to see in our framework. Currently, we are looking into Spark, Flink and Storm as potential alternative to our proposed design. We are maintaining google doc which lists required use cases and capabilities in airavata. The purpose of this document is to discuss and compare different tools and their compatibility against the listed use cases. please feel free to add suggestions and your views.
Work Summary
As a part of class projects I worked on following things;
- Data management across mutiple miscoservices in distributed environment.
- 2 phase Commit
- Event based database replication
- Distributed workload management.
- Statefull Design
- Stateless Design
- AKKA approach
I have discussed all these in great details in my earlier blogs.